由来
买了几本书,其中一本还买错了版本了,真是疏忽。本着练习的原则写了一个爬虫,代码是基于书本和搜索引擎的。
只是简单的爬取了Top100的榜单,没有一些扫操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def get_ranking_list(url):
try:
html = urlopen(url)
except HTTPError as e:
print(e)
try:
bsObj=BeautifulSoup(html.read(),'lxml')
movie_list=[]
for x in bsObj('dd'):
ranking = x.find('i').get_text()
board_img = x.find('img',{'class':'board-img'}).attrs['data-src'].replace('@160w_220h_1e_1c','')
name = x.find('p').get_text()
star = x.find('p',{'class':'star'}).get_text().strip()
release_time = x.find('p',{'class':'releasetime'}).get_text().strip()
score = x.find('p',{'class':'score'}).get_text().strip()
movie_list.append({'ranking' : ranking,'board_img' : board_img,'name' : name,'star' : star,'release_time' : release_time,'score' : score})
return movie_list
except AttributeError as e:
print(e)
if __name__ == '__main__':
ranking_lists = get_ranking_list('https://maoyan.com/board/4?offset=0')
for i in range(10,100,10):
ranking_lists.append(get_ranking_list('https://maoyan.com/board/4?offset='+str(i)))
print(ranking_lists)
|
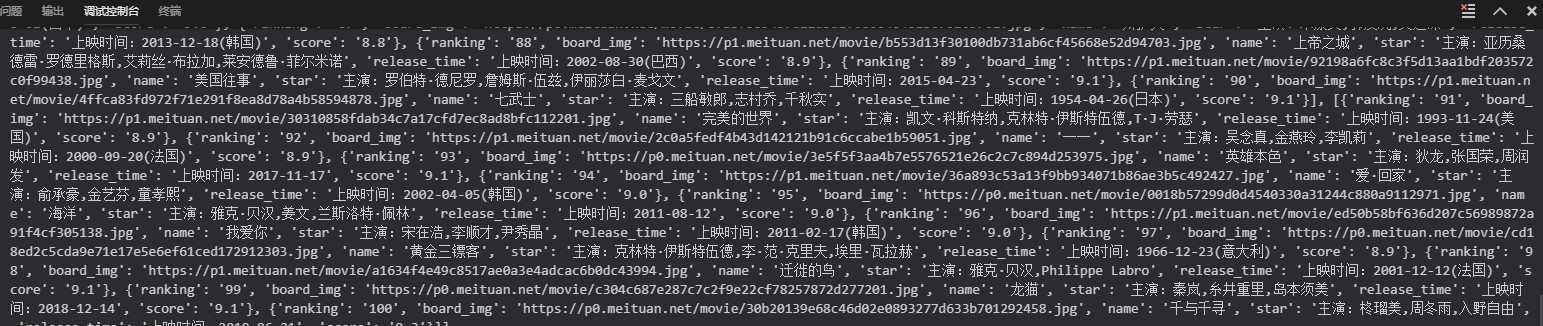
运行结果
知识点
- BeautifulSoup的简单使用